浅析hashmap的put()方法 |
您所在的位置:网站首页 › put on › 浅析hashmap的put()方法 |
浅析hashmap的put()方法
|
最近面试的时候,有面试官问到hashmap的put()方法做了哪些事情,我觉得回答的不够好,特此好好研究下hashmap,并总结下. HashMap 主要用来存放键值对,它基于哈希表的Map接口实现,是常用的Java集合之一。 JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间 先看下hash()方法: static final int hash(Object key) { int h; // key.hashCode():返回散列值也就是hashcode // ^ :按位异或 // >>>:无符号右移,忽略符号位,空位都以0补齐 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }反正就是按照一系列的算法得到一个int类型的hash值,再看看putVal()方法: final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node[] tab; Node p; int n, i; // table未初始化或者长度为0,进行扩容 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中) if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 桶中已经存在元素 else { Node e; K k; // 比较桶中第一个元素(数组中的结点)的hash值相等,key相等 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // 将第一个元素赋值给e,用e来记录 e = p; // hash值不相等,即key不相等;为红黑树结点 else if (p instanceof TreeNode) // 放入树中 e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value); // 为链表结点 else { // 在链表最末插入结点 for (int binCount = 0; ; ++binCount) { // 到达链表的尾部 if ((e = p.next) == null) { // 在尾部插入新结点 p.next = newNode(hash, key, value, null); // 结点数量达到阈值,转化为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); // 跳出循环 break; } // 判断链表中结点的key值与插入的元素的key值是否相等 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) // 相等,跳出循环 break; // 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表 p = e; } } // 表示在桶中找到key值、hash值与插入元素相等的结点 if (e != null) { // 记录e的value V oldValue = e.value; // onlyIfAbsent为false或者旧值为null if (!onlyIfAbsent || oldValue == null) //用新值替换旧值 e.value = value; // 访问后回调 afterNodeAccess(e); // 返回旧值 return oldValue; } } // 结构性修改 ++modCount; // 实际大小大于阈值则扩容 if (++size > threshold) resize(); // 插入后回调 afterNodeInsertion(evict); return null; }提一点,这里存入Node[]数组的下标是用的(n - 1) & hash这样得到的,这样有什么好处呢? java的与运算: 运算规则:0&0=0; 0&1=0; 1&0=0; 1&1=1; 即:两位同时为“1”,结果才为“1”,否则为0.下面结合两个例子说明: 再看上面的运算,只有当所有的容量减一后的数据都是高位,这时运算之后产生hash碰撞的几率就会减小,这也是为什么hashmap里面的数组大小都是2的幂次倍; 结合初始化hashmap里面的方法,对于给定容量的hashmap,它的大小始终是2的幂次倍. static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }简单总结下put()方法的流程: 执行hash(Object key)得到一个int类型的hash值,然后根据这个hash值就可以找到Node节点的位置了; 判断table是否为空,为空表明这是第一个元素插入,则使用resize()进行扩容,初始大小默认16; 如果table为空,说明没有产生hash碰撞,则直接插入node节点,调到第5步,否则进行下一步; 如果table不为空,进行下面三种判断: 1.桶中第一个元素(数组中的结点)的hash值相等,key相等,赋值给node节点e; 2.hash值不相等,说明key不相等,为红黑树,放入树中,赋值给node节点e; 3.hash值不相等,说明key不相等,为链表,遍历链表,赋值给最后一个节点,并返回node节点e(这里面还有长度的判断,当链表长度大于8之后需要将链表转化为红黑树进行存储); 判断新插入这个值是否导致size已经超过了阈值,是则进行扩容 上面的总结可能不是很准确,具体情形还是要看上面代码的注释,不过总体流程是这样的. |
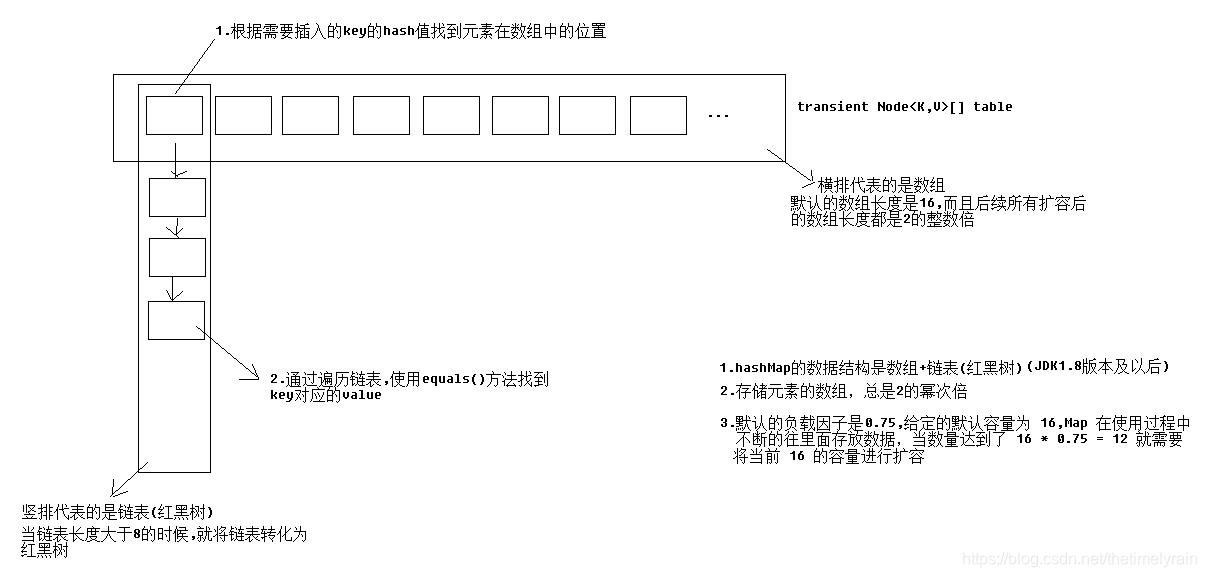 不多废话,之间看下hashMap的put()方法;
不多废话,之间看下hashMap的put()方法;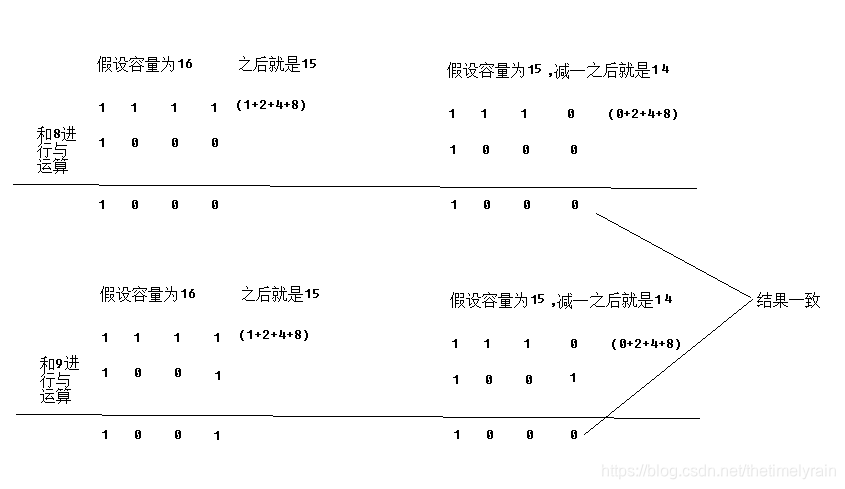 前面说到,hashmap主要是用数组维护数据结构的,当数组里面的元素位置尽量的分布比较均匀的时候,那么这个数组里面的链表就有很大几率是只有一个元素,这样遍历数据的时候就十分方便,所以我们要做到的是尽量将不同hash值的数据放到不同的数组位置.
前面说到,hashmap主要是用数组维护数据结构的,当数组里面的元素位置尽量的分布比较均匀的时候,那么这个数组里面的链表就有很大几率是只有一个元素,这样遍历数据的时候就十分方便,所以我们要做到的是尽量将不同hash值的数据放到不同的数组位置.【本文地址】
今日新闻 |
推荐新闻 |